1 Introduction
Our project is to do literature analytics on female image in literature works of American Chinese authors. After a hundred years of development, American Chinese literature has made remarkable achievement, the female characters in those works have their own style and particular characteristics, and they also reflect the author’s consciousness. At the same time, identification consists of an individual’s sense of selfness and group awareness could reflect how one understands and responds to others. In our project we want to find out the specialty of female character in the literature works of American Chinese authors and we decide to explore one’s racial-ethnic identity can create a sense of understanding through conceptualizing past perceptions in to new and positive ideals of the selfness and group awareness.
We collect 22 literature works that contain female images from 12 American Chinese Authors. The data are online open sources with epub, mobi, and pdf format. We use Python to do information extraction, POS-TAG, and sentiment analysis. After that, we use SPSS modeler to do sentiment analysis on all 22 literature works and also on 6 literature works that written by Amy Tan.
The majority of female come from different background and they are in lower social status facing with innumerable difficulties from society and culture. And the traditional female images are courageous, tough, taciturn, and thoughtfulness under the social background of the old time.
2 Dataset Description
Our original data contains 22 literature works of 12 Chinese American authors, which are from online open source and their formats are epub, mobi, and pdf. Raw data is transformed to text file.

The reason why we choose these data is that all the main female characters in these literature works have something in common. They are all portrayed by Chinese American authors and live in the same age–20 century and same country–United States.
3 System Design
3.1 Data Preprocessing
In this part we collect the fiction files from different sites including different types of files like txt, epub, etc. Here we transformed these text data into txt files and load it into the python for further use.
The second step for this section was tokenize. Here we process the job in two parts. On the one hand we tokenize the text data into separate sentence and save them as a new txt file. This data set which consists of separated sentences is useful for our text analysis in the SPSS Modeler and the sentiment analysis in python. On the other hand, we tokenize the same raw data in to words for pos-tagger analysis and frequency research. In both parts we perform standardization on the text data. For sentences, we transformed the text to lowercase and delete useless signals. For words, we transformed the words to lowercase and drop the stopwords and non-letter signals for better analysis.
3.2 Information Extracting
Since our purpose is to analyze the characteristics of female figures in the works of Chinese American authors. So, in this step we will extract the text which describes the female figures from the whole text file.
In order to archive it, we first check several fictions manually about the descriptive words for female figures. One important conclusion is that continuous text describing a woman’s action and figure won’t exceed 5 complete sentences. (Here we define sentences by dots and other ending punctuation signals.) So, we will apply the approaches below to extract the needed text: Extract names from the fiction text.
- Extract names from the fiction text. (Here we only extract the names for main female characters in the fiction.)
- We search the sentences which contains the names extracted in the previous step and locate them.
- For each sentence located, we check the previous 5 sentences and the next 5 sentences and add all the sentences which describes the female figures in to the processing dataset. Here we judge whether a sentence is a description by check if there are certain keywords in this sentence. For third-person fictions, we will use “her”, “she”, and some words connecting with the woman figure like “woman”, “lady”, “ms”, etc. For first-person fictions, we will replace “her”, “she” with “I”, “me” and other similar terms.
- When we check all the sentences in a fiction, we will delete the repetitive sentences keep these sentences as the processing dataset.
3.3 Concept Frequency and Classification
In this step we will use SPSS modeler to load the processing data generated in the previous step and perform the concept term frequency and concept classification on the processing data. Here words, especially nouns, with high frequency indicates the frequent topic or events happened in the fiction. We can generate important concepts from the processing data and these concepts will help to deepen our understanding of the fiction.
Besides for the topic and events, the adjective and descriptive concepts with high frequency will indicates the potential feeling and attitude of authors upon the character. This will help to extract the writing characteristics from the text dataset.
3.4 Pos-Tagger
In this step we will use python to identify the position information of all the words in the processing dataset. For example, whether the word is noun or verb, or comparative adjective or other kinds of words. After recognizing the word type, we will count the number of words with different word type. Since previous literature analysis research has shown the correlation between the frequency of different word pos-types and the quality of the works. So, the distribution for words of different pos-types will help us to evaluate the fictions and the patterns of these fictions in describing the female figures. Here we will use the pos_tag function in nltk package to perform this section.
3.5 Sentiment Analysis
In this step we will use python to perform a sentiment analysis on the processing text data. In the fictions authors may indicates their attitudes and thoughts towards the characters by using words with sentiment. So, the sentiment analysis for the fiction text will reflect the authors’ opinions on the characteristics they constructed, which will help to deepen our sight into the fictions and our standing of the female figures in the fictions. Her we will use the sentiment intensity analyzer in the nltk package to perform this analysis and generate the positive and negative scores for all the sentences. Then we may check the sentiment for the whole text to understand it.
3.6 Clustering
In this step we will apply the machine learning methods upon the processing data to generate potential clusters for the sentences dataset. Through this process, we want to find similar sentences clusters which may describe the same part of female figures and check their sizes and contents.
To complete this, we will choose proper concepts according to the frequency and content of them and transformed information of these concepts into a series of binary variables according to whether the words for a certain concept exist in the sentences. Then we may perform all kinds of clustering models using these binary variables.
4 System Implementation
4.1 Sentiment Analysis in Python
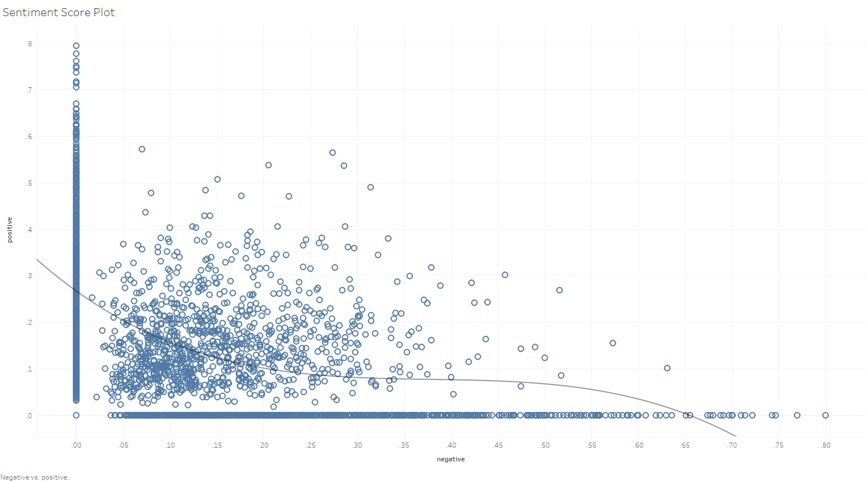
The line here in the chart represents the trend line of the sentiment score for each line of all 22 novels. The polynomial number is set as 3. From the trend of the line, we can see that the sentiment scores tend to be negative. That means the female image in the novel of American Chinese authors is technically negative.
4.2 Concepts Frequency and Classification and Clustering in SPSS
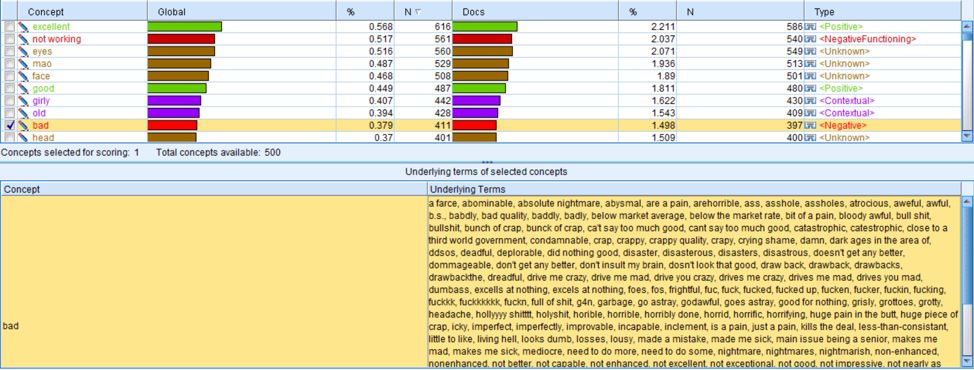
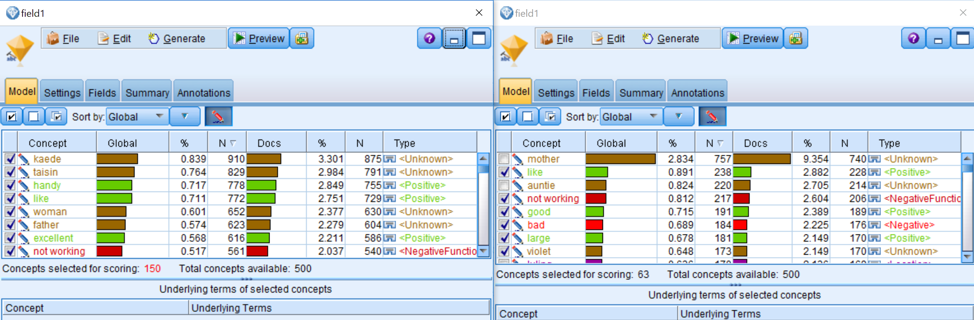
Based on what we get from SPSS, we can figure out why the descriptive part for female characters is negative. The concept bad appears 411 times in total. Taking a deeper look into the text, we can find that a lot of bad language are used, like shit and suck. Since these words present around the place where the main characters are in the context, we speculate that these characters tend to use bad language in their daily life and the social status is relatively low. Besides, words like made me sick, just a pain, painful, not the best quality and piece of crap, reflect the living situation and the things happen around the main characters are not satisfying. We assume that the authors focus on descripting the tough living condition and life of American Chinese female.
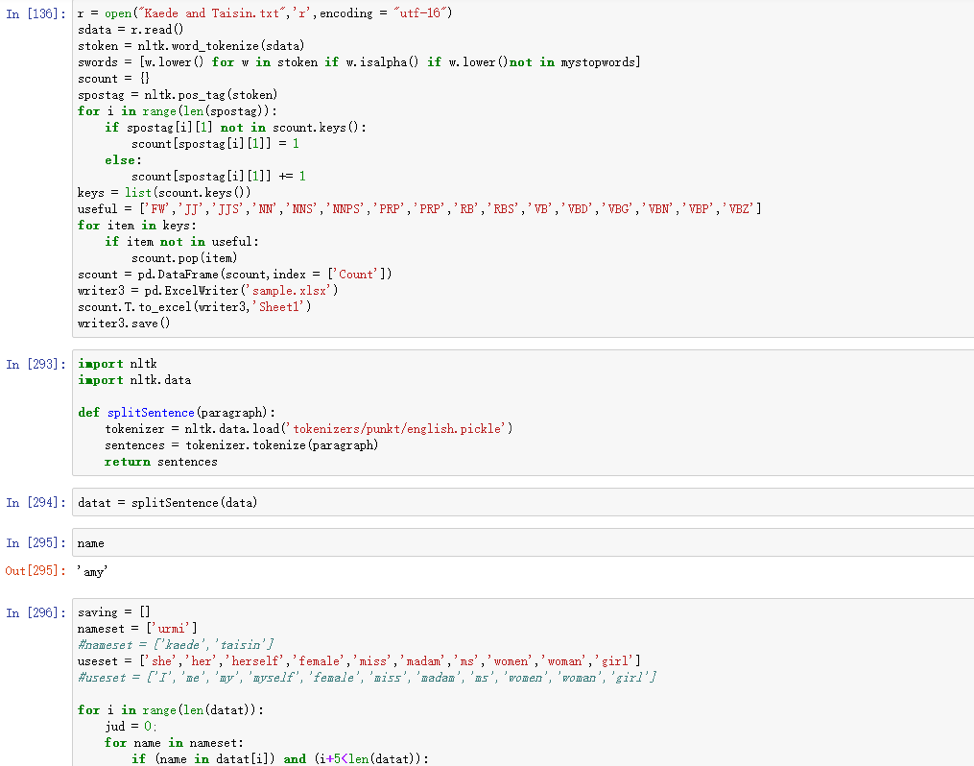
4.2 Parameter Setting
- From the SPSS Text Analytics palette, add a Text Mining node to the stream and connect it to the Var File node.
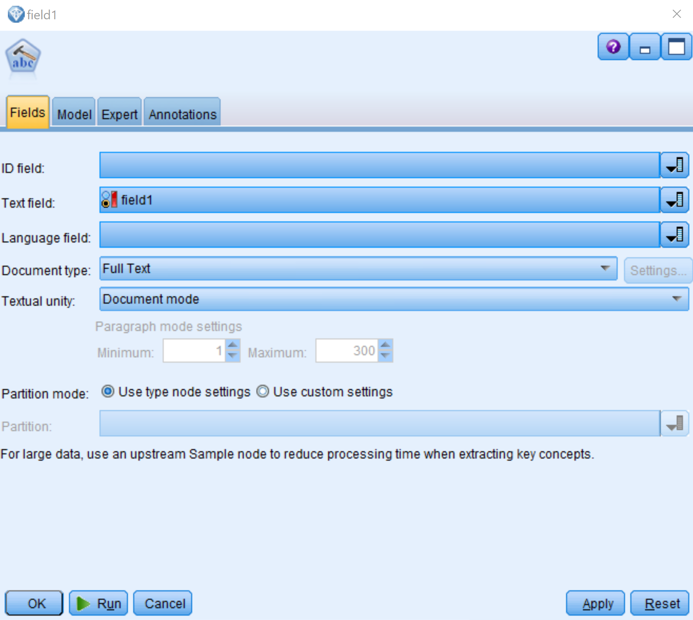
- Edit the Text Mining node, on the fields tab, click the Text Field chooser, and then select field1.
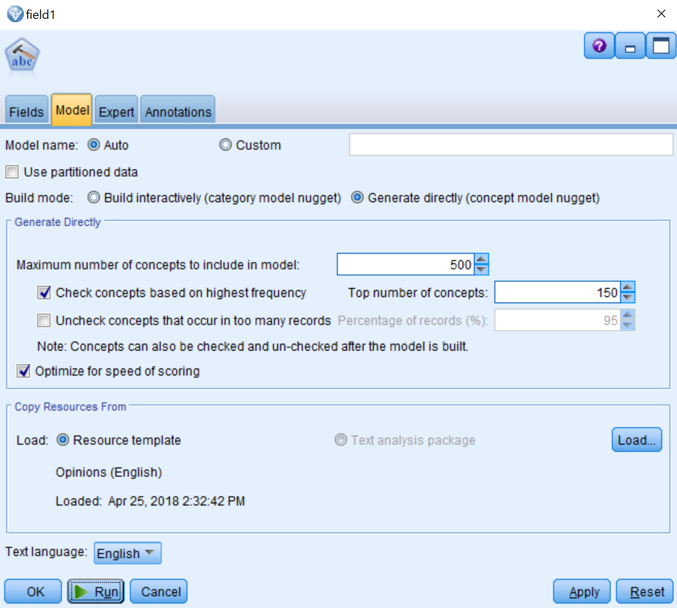
- Click the Model tab, and then select Generate directly (concept model nugget).
- Select Check concepts based on highest frequency, and then beside Top number of concepts, enter 150.
- In the Copy Resource From section, click Load. Click the Opinion (English) template to select it.
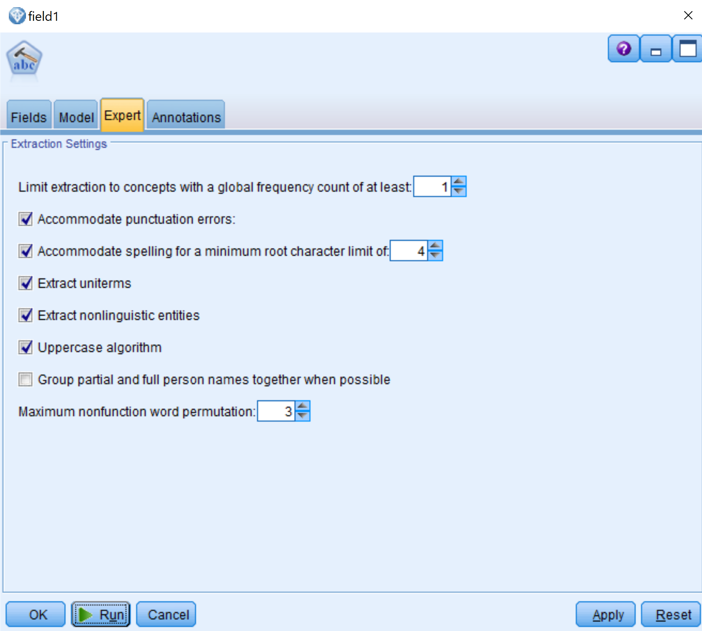
- Click the Expert tab, select Accommodate spelling errors for a minimum root charter limit of, and then specify 4.
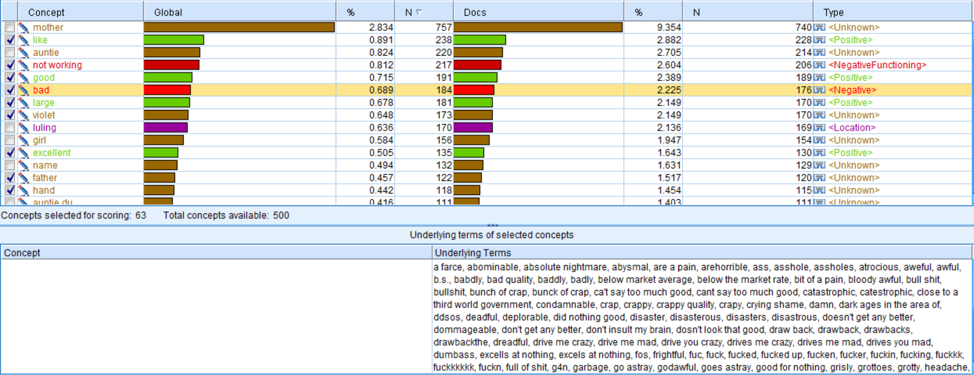
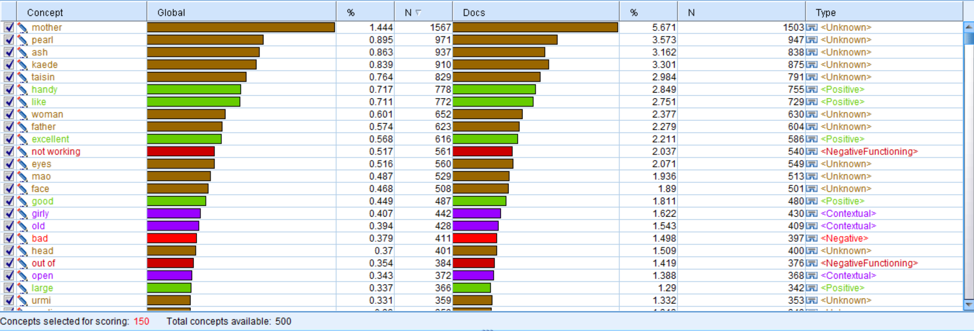
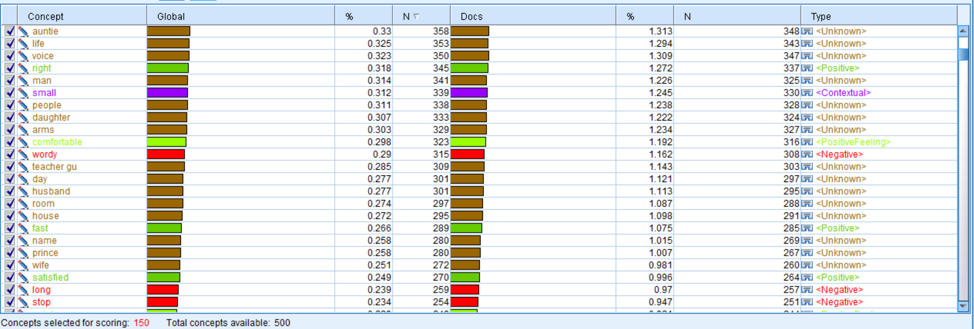 Comparing the concepts of Amy Tan’s 6 novels and those of all novels, we find that the female image in Amy’s novel is in consist of what is analyzed previously. In the concept bad, the collected words have a large overlapped part. And further, we hope we can figure out the detailed reason why those bad concepts are used. So, we plan to do clustering analysis.
Comparing the concepts of Amy Tan’s 6 novels and those of all novels, we find that the female image in Amy’s novel is in consist of what is analyzed previously. In the concept bad, the collected words have a large overlapped part. And further, we hope we can figure out the detailed reason why those bad concepts are used. So, we plan to do clustering analysis.

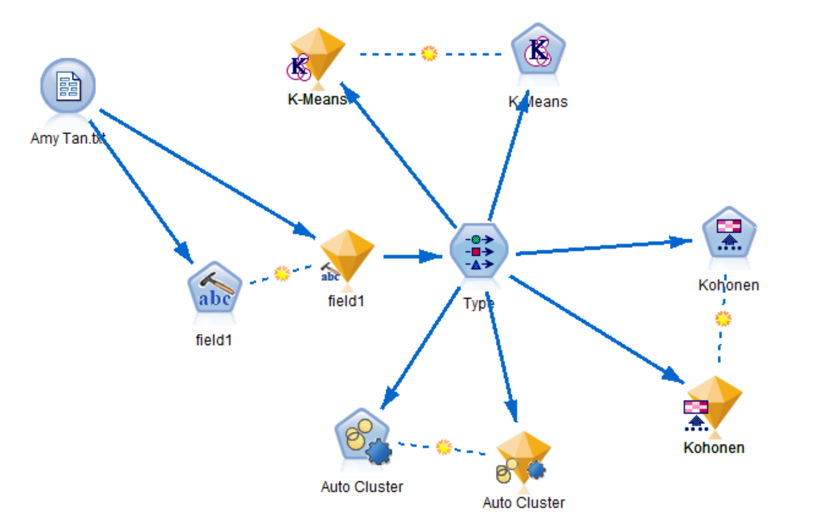
We use auto cluster to let the machine choose the best model to do clustering analysis. We tried two suitable models to cluster the concepts. It is unsurprising that we get too many clusters (42 are our best results), which do not make sense or cannot be explained. But based on what we have learned, we do not have a more intelligent method to achieve our goal.
5 Use of Tools
We use Python to do POS-TAG for all 22 literature works, information extraction for 22 literature works, and sentiment analysis on only 6 literature works that written by Amy Tan. We do sentiment analysis on 6 literature works that written by Amy Tan because we want to do analysis on what is the female image under one of the Chinese American author; at the same time, Amy Tan has the most literature works in our datasets compared with other Chinese American authors.
We use SPSS Modeler to do sentiment analysis on all 22 literature works and do cluster only on 6 literature works written by Amy Tan.
6 Tableau Visualization for POS-TAG Results
Compared with Figure 17, we can see the word type frequency of all 12 authors. From the bar chart, NN (Noun, singular or mass) is at the top of two lists and VBD (Verb, past tense), JJ (Adjective), PRP (Personal pronoun), and RP (Particle) belong to the most frequency word group.From Language Log, Usage Advice, we found that for popular fiction and non-fiction writers, noun and verb are the most frequent words. Although differences in POS distributions are a symptom, not a cause, we can still see that the novels written by these 22 American Chinese authors have the similar word usage preference.
7 Evaluation
We choose one of the most popular American Chinese authors to evaluate our result. Amy Tan is chosen. Based on six novels of her, we analyze the word type frequency. It is pretty clear that in terms of word type frequency, the writing style of Amy Tan is in consist of the group of authors.
After comparing the result of all 22 literature works in our dataset with 6 literature works that written by Amy Tan, we find that as the most famous American Chinese Author, her literature works satisfy the main trend of all American Chinese literature works. Therefore, if the publishers want to choose a book that has similar background and similar plot, and try to attract more readers, they should compare the new book to our model analysis, which could help publishers to better control their budget and predict sales more accurate.
8 Limitation
We only choose one main female character of each book and choose limited literature works of 12 authors. In this case, we may not be able to obtain the authors’ attitudes towards female image and their language habits.
Our selection of words is not scientific because we may extract some irrelevant information or words originally used to describe other character. For example, when the character talks about other person, these words will be extracted according to our code, but these words are supposed to portray other character.
In our evaluation, we only choose one literature work Huntress to test our model. However, it is possible that the female characters of Huntress don’t have something common with that of other 21 literature works.
As for our sentiment analysis, we conclude that the female characters in the chosen novels are portrayed negatively. The reason why this phenomenon occurs is that the author has gender discrimination, or women at a particular time have a very low social status.
9 Conclusion and Further Direction
In conclusion, we find that sentiment scores tend to be negative according to our analysis. At the same time, we notice that female is in lower social status, their living situation is tough, and traditional female images are courageous, tough, taciturn, and thoughtful. However, we think 22 literature works from 12 American Chinese authors are not enough dataset to do completed analysis, we should find a better scientific way that can find exact words to describe the main characters in the literature works, and we think the character networking in the literature works could help us to do better literature analysis.
10 Reference
- “Use Good Words, Not Bad Ones.” The Economist, The Economist Newspaper, 25 Mar. 2015, www.economist.com/blogs/prospero/2015/03/johnson-writing-style.
- “Language Log.” Language Log » Moar Verbs, Mark Literman, 24 Mar. 2015, languagelog.ldc.upenn.edu/nll/?p=18398.
- “POS Tagging.” POS Tagging - CSDN Blog, Fxjtoday, 26 Aug. 2010, blog.csdn.net/fxjtoday/article/details/5841453.
- Socher, Richard. “Deep Learning for Sentiment Analysis - Invited Talk Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, 2016, doi:10.18653/v1/w16-0408.