1 Introduction
In the animal shelters, some get to be adopted by a loving family, whereas some are not. It is very important for the shelter to know whether the pet is more or less likely to be adopted, so they are able to make future decisions. In this project, the goal is to figure out correlation and which factors have influence on potential pet adoption, for instance, the pet’s sex, age, color, etc.
There are 3 major steps for this project: pre-analysis, modeling, and outcomes.
In the stage of pre-analysis, the main procedure is data manipulation, which transforms string variables into categorical variables, and reduce the number of categories, so that the predictors are functional without causing problems to the model, i.e., insignificance, multicollinearity, and overfitting. Meanwhile, we use scatter plot matrix to visualize the correlation between different variables. Missing values are processed by MD imputation.
In the stage of modeling, we use logistic regression model to predict which variables have influence on potential pet adoption. Feature selection are also used to pick reasonable scales of predictors.
2 Pre-analysis
2.1 Summary Statistics
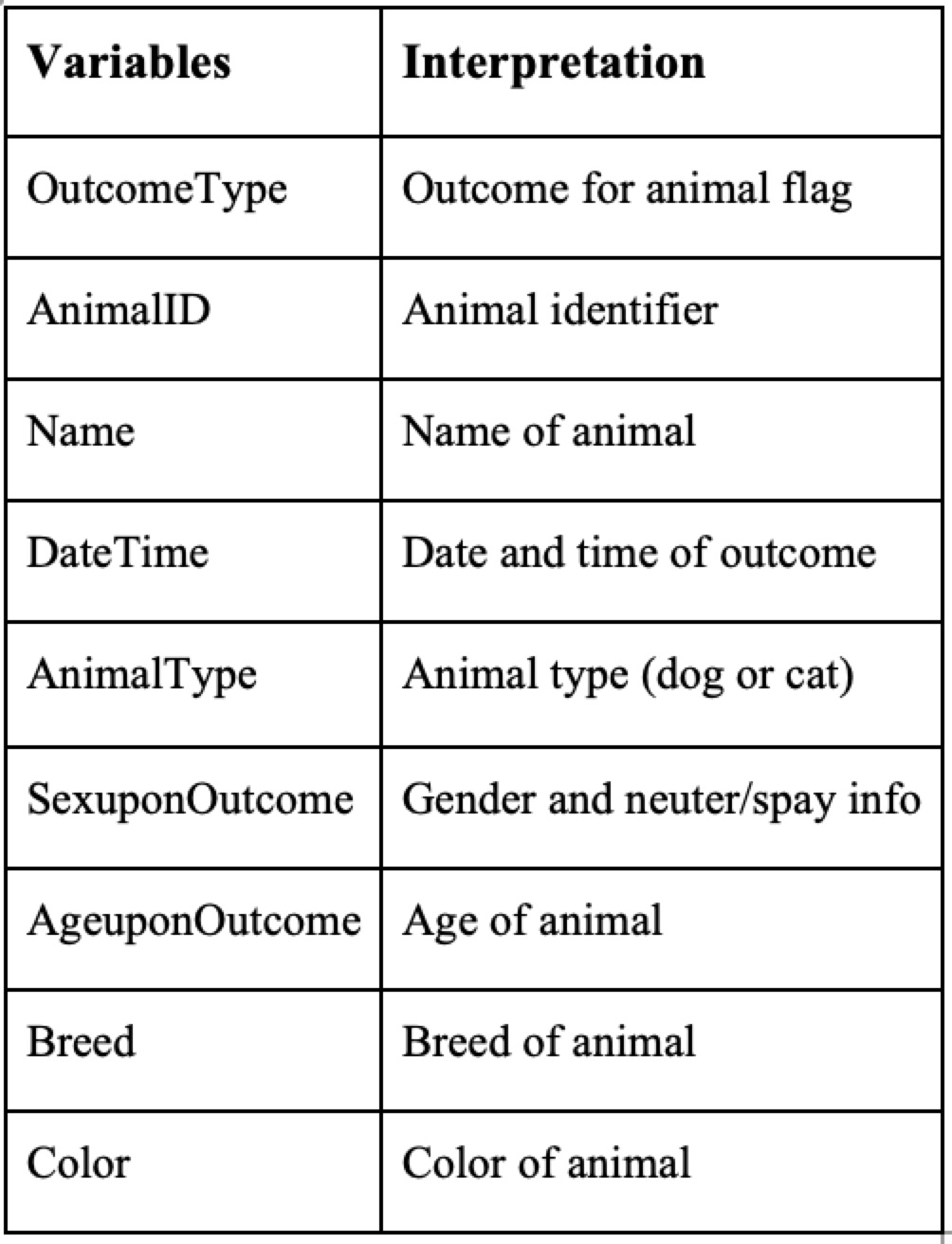
The interpretation of variables is shown for the original data.
2.2 Feature Development
In the original dataset, most variables are string and holding lots of information, but after transforming the string variables are transformed to categorical, the variables still seem not appropriate for building regression models. Especially for the two variables breed and color, there are simply too many categories, each of which would get an individual coefficient if they were directly put into a regression model.
2.3 Variable Transformation
Multiple steps of transformation are applied to the dataset. Age is normalized into number of days; sex upon outcome is spitted up into 2 variables - sex and neuter status; breed is simplified into 3 types - pure, clear mix (with known breeds for parents), and unclear mix (only one parent breed known); color is also simplified into 2 types depending on if the animal has a mixed color; the animal’s name is also simplified into a flag indicating whether it has a name; the adoption date is also transformed to contain only the month information. In the meantime, the missing values in the age variable is generated by MD imputation.

2.4 Imputation
After the variable transformation, we found 18 missing values in Age variable. It seems not to affect our result since we have a large dataset. However, we would still like to impute these data by MD imputation.
We combined the first 100 observations with all observations that have any missing value. The plot of proportions of missing variables shows the missing value is about 15% of the whole sample data.

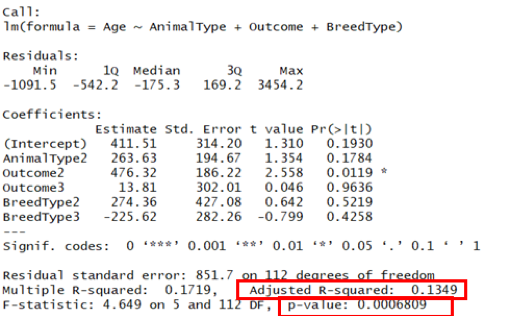
We used mice function in R to impute 5 datasets. A linear model is fitted to the imputed dataset. R will estimate our regression model separately for each imputed dataset, 1 through 5. We then need to summarize or pool those estimates to get one overall set of parameter estimates. After comparing Adjusted R-squared and p-value among all the outcomes, we could say that imputation 5 performs better, which are what we will used to supplement the missing data.
Although the result is not good enough. But it wouldn’t affect our model building, since 18 variables is nothing when we have a dataset of 26,729 observations. The good thing is we filled up the missing values.
3 Exploring Potential Correlations – Initial Plots
It is inevitable that most of the predictors in the model would be categorical, and thus the pair scatter plots do not tell us much about the dataset.
It can be seen that the animal age is primarily distributed at a very low level (below one year old). It also seems that the animal type (cat/dog) may be correlated with the outcome, and also with whether the animal has a mixed color. However, the correlation between most other predictors tend to be rather random.
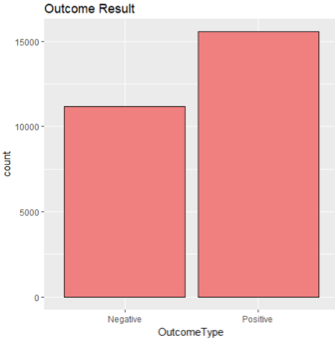
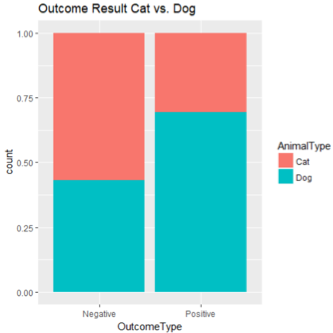
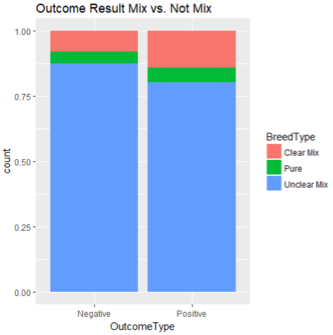
The first plot tells that the target variable is fairly balanced - positive results take up less than 60% of total number of observations. From the next plot we could tell that over 70% of the dogs in the sample have positive adoption results, whereas the number is only around 40% among cats. Maybe dogs are more popular than dogs under adoption condition. The last plot says that most dogs and cats are labeled ‘unclear mix’ for their breed, meaning the pet is only similar to, or is known as a child of, a known breed, but the parent status are basically unclear.
4 Initial Hypotheses
Based on the common sense of pet adoption, a younger cat or dog is more likely to be adopted than the older ones, but according to the previous pair plots, this is not really obvious.
One can also guess that the neutered/spayed pets are more likely to be adopted since it’s better for pet’s health and also saves medical fee. So are the pure-breed pets, compared to the mixed, one of whose parents’ breed is unknown.
And according to the pair plots: dogs may be more likely to be adopted than cats; those of mixed color are more likely to be adopted than those of pure color; and having name also brings a higher chance of adoption.
5 Modeling
The Logistic regression is designed to solve the binary-target prediction, which makes it the suitable choice of predicting whether a pet would be adopted. And also amounts of positive and negative outcome are fairly balanced, so it’s rational to use this method. All further steps are set based on the Logistic regression.
5.1 Feature Selection
Predictors are selected through a forward stepwise subset regression. All of the 8 potential predictors are set as input.
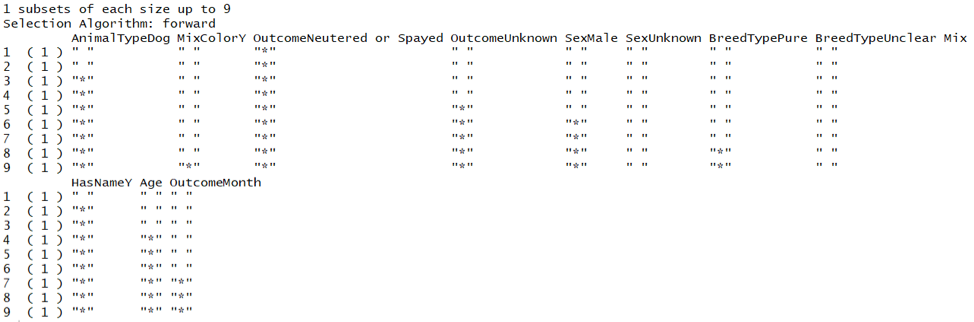
The Bayesian Information Criterion (BIC) value is calculated for each step, and it is found that the 5th step has the lowest BIC, meaning that it is more reasonable to use the set of variables in the 5th step.
5.2 Model Building & Result
Two models of Logistic regression are built. One takes all independent variables as input, and the second model takes only the predictors kept after the previous feature selection.
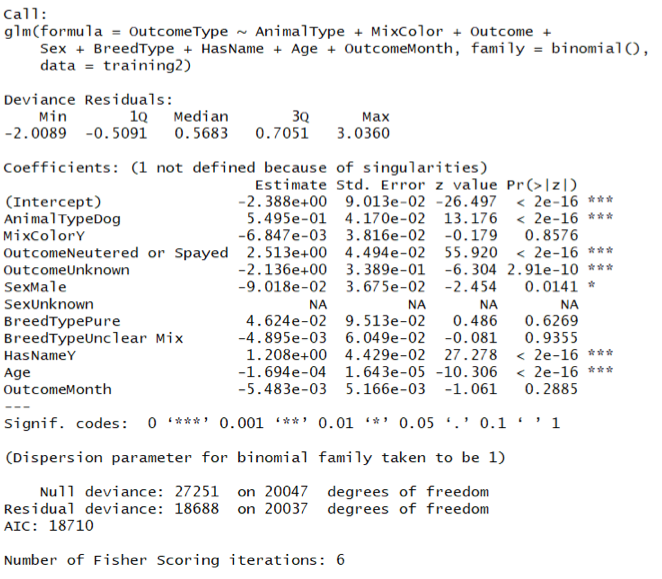
Model 1 is built by all 9 variables, and there are 4 selected variables included in Model 2. Compared with these two regression models (as shown in Figure 10a and Figure 10b), we could see that for model 1 we could tell that most of the predictor coefficients are significant, while all the coefficients of predictors for model 2 are significant.
More importantly, the AIC value of model 2 is slightly less than that of Model 2. Meanwhile, we also use null deviance and residual deviance to test which model is better fitted. It proves that the p-value of Model 2 is smaller than Model 1, which further illustrates that Model 2 is better than Model 1.
An ANOVA Chi-squared test is also conducted to compare the results of the two models.
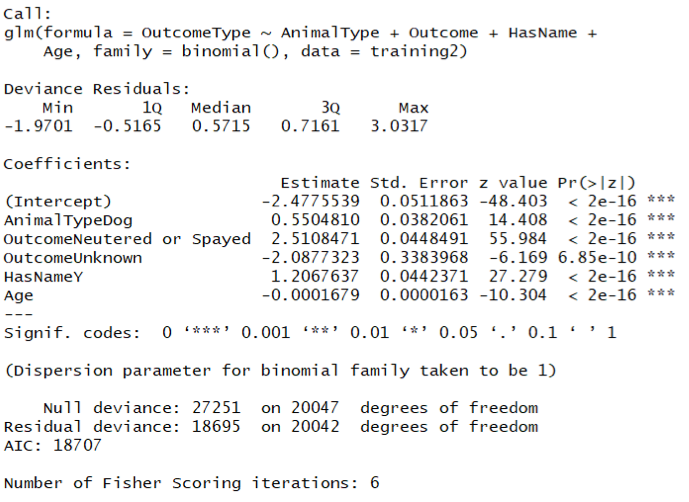
Comparing Model 1 and Model 2 by ANOVA test, the p-value of Model 2 is 0.1795. Meanwhile, although the values of residual degree of freedom and residual deviance have slight difference, the difference value of residual degree of freedom and residual deviance in model 2 is smaller than that in model 1, which proves that Model 2 has better performance than Model 1.
5.3 Model Evaluation
The model has an accuracy of 80.95% in the training dataset and has an accuracy of 81.37% in the testing set. It is proved that the model does not overfit.

Bootstrap cross validation is also conducted to evaluate the model. The process iterates 10 times - in each of iteration, the dataset is randomly partitioned into a training and a testing set, and a model is trained on the training set and the accuracy is checked on the testing set. 10 iterations give us 10 results of accuracies, of which the distribution. The results are distributed around 81%, showing a robust prediction of the target variable.


6 Conclusion
6.1 Predicting Conclusion
With the model built and validated in the last section, it is now possible to predict whether a cat or dog in the animal shelter will be adopted. The trained model is expected to have a robust performance on any incoming record of new data with the same format, and predicted probability is expected to have an accuracy around 80%.
In terms of the impact of the factors, some of the previous expectations were proved correct whereas some were not. Generally, there are some simple rules that people can follow while making the judgement:
Animal type (cat or dog), outcome (neuter/spay info), having a name or not, and age are the most influential factors that lead to different adoption outcome in this prediction. More specifically, an animal which is neutered or spayed, has a name, and is dog tend to have a positive outcome (adoption, returned to original owner). What’s more, the younger it is, the higher chance of positive outcome it gets. In the contrary, an animal with unknown neuter/spay info would likely to end up with a negative outcome (euthanized, transferred to other shelter).
6.2 Possible Future Improvements
The data is to a large extent simplified to fit into the Logistic model, and in the meantime lost a great proportion of information, such as the pets’ color and breed. The model is not able to predict if a certain breed of cat or dog is more popular than others, which seems to be a concern by pet lovers over time. With text mining techniques being applied to the pets’ breed and color information, it would be possible to group the pets into clusters based on their similarity on color and breed. If there is truly a trending for, say, popular breeds, it could be a better predictor of the adoption outcome, which would provide the animal shelters with a better prediction.